Site Reliability Engineering (SRE) for Enterprise
Recently, I engaged in some study as part of my preparation for the Professional Cloud DevOps Engineer Certification, which I undertake once or twice a year as a structured learning effort to address knowledge gaps and broaden my expertise.
Throughout this preparation journey, I encountered a particularly valuable module titled Developing a Google SRE Culture in the context of Site Reliability Engineering (SRE). This module proved to be beneficial across various domains, including software engineering, data engineering, analytics, and machine learning. It addressed a common challenge: how to assess and enhance service quality to deliver a satisfying user experience. This is precisely where SRE plays a pivotal role.
In this article, I aim to share my insights in five distinct areas that have provided me with enlightening moments. I will explain why these insights hold significant importance for enterprises. However, before delving into these areas, let's establish a foundational understanding of SRE by covering some basics.
What is Site Reliability Engineering
Site Reliability Engineering (SRE) is a way of making sure websites and online services work well all the time. There are a few important terms you should know.
SLI stands for Service Level Indicator. It's like a measure to check how well things are working. For example, it can be the percentage of successful transactions on a website.
SLO is Service Level Objective. It's like a goal we set for how well we want things to work. For example, we might say we want 99% of transactions to be successful.
SLA is Service Level Agreement. It's like a promise we make to our users. We tell them that we will aim to meet the SLO, and if we don't, we'll make it up to them somehow, like offering credits or discounts.
Error Budget is not a term you may have seen. Consider it like a "mistake allowance". It's the amount of errors or problems a service can have before it's considered unreliable. SRE teams work to stay within this budget to ensure the service remains reliable for users.
So, SRE is all about making sure websites and services are reliable, measuring how well they are doing (SLI), setting goals for their performance (SLO), and promising users that we'll meet those goals (SLA). The Error Budget is calculated as the difference between the SLO and SLA, and usually, this measurement is done over a 28-day period. If there isn't sufficient Error Budget remaining, it can impact the choices made regarding introducing new features because it might jeopardise the SLA.
How important is SRE
This is a very interesting topic, and throughout my experience over the past years in multiple enterprises, SRE is often either not applied at all or over applied. They both seem to leads to very interesting but troublesome outcomes.
- No SRE, a team that's skilled but lacks discipline can achieve quick initial success in delivering value, but their systems may soon become disorganised and unmanageable.
- No SRE, a skilled and disciplined team can also achieve initial success, delivering value relatively fast, and maintain their systems well with rare issues. However, they might occasionally face very chaotic situations where outages can last for days without anyone noticing.
- In cases where there are many SREs or dedicated SRE engineering teams, there's a risk of over-applying SRE practices, sometimes prematurely, when the business isn't fully prepared or convinced of their benefits. This can result in excessive overhead and harm the value delivered to the business.
The second point is particularly fascinating to me, and it usually characterises the category that the teams I've led often find themselves in. Personally, I take a highly disciplined approach to engineering leadership and prefer not to deal with crises. Over the years, my goal has always been to embed quality into the design of all systems to make them as resistant to breaking as possible, while keeping the design straightforward.
However, it becomes clear, especially after completing the SRE module from Google, that striving for engineering excellence without implementing SRE practices is not the right approach. While you may receive nice words from stakeholders and take pride in saying, "the systems I work on rarely break," it's important to recognise that achieving 100% reliability in any system is physically impossible. When that inevitable rainy day arrives, it can be an emotionally devastating moment, not just for yourself but, more importantly, for the talented engineers working alongside you.
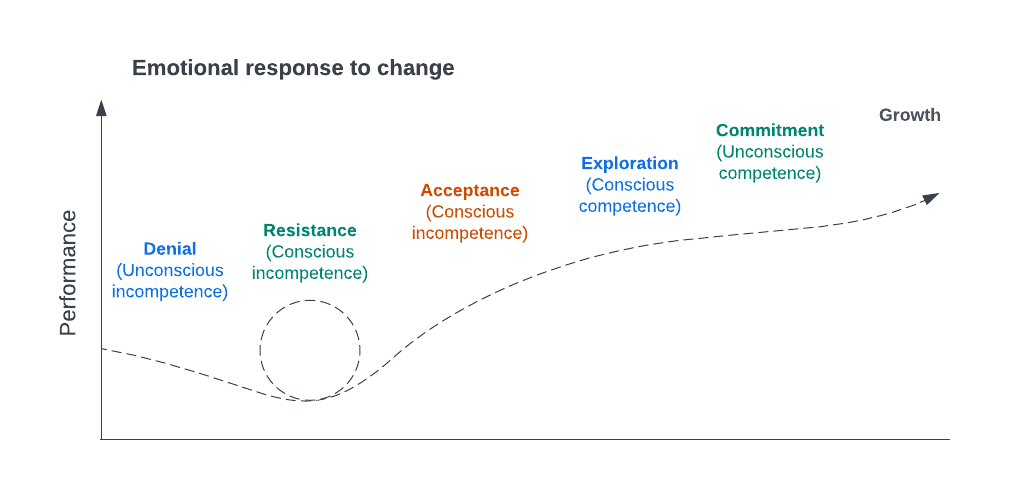
There's an interesting illustration caught my eye, and it's like a lightbulb moment all of sudden made sense to all my unanswered system reliability questions
But you may ask, what is the correct way of doing it, and how?
The emotional response to change
There is no definitive right or wrong; rather, it's about what proves effective and what doesn't. Achieving success in this area can be quite complex.
Before diving into any specific SRE practices, particularly within a large organisation, the utmost priority revolves around the cultural aspect. In simpler terms, it pertains to how prepared an organisation is for change and how individuals will emotionally react to it. In my perspective, comprehending this aspect is crucial before introducing SRE practices.
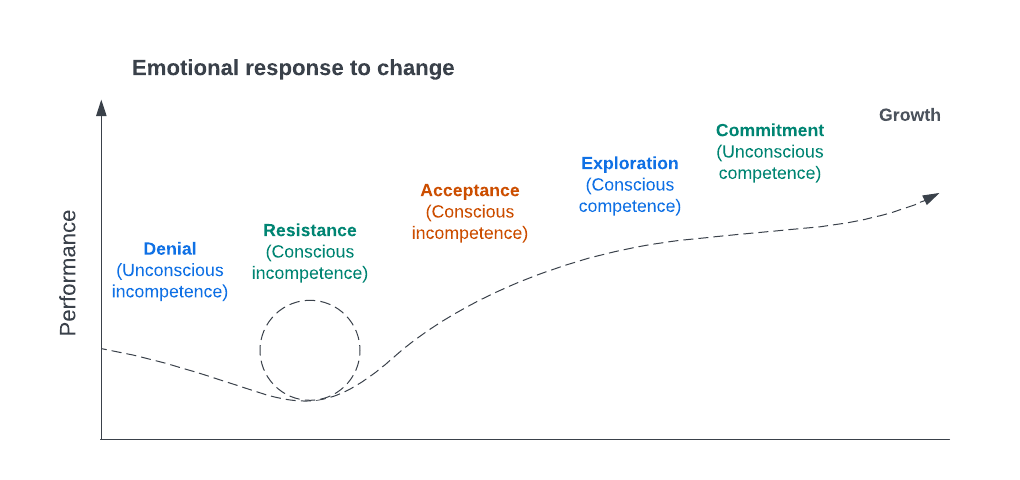
The illustration shows the Emotional response to change illustrates how individuals generally react at various stages when confronted with change. I believe many of you can easily identify with these emotions, and they may resonate with you as soon as you see them.
This model consists of six distinct stages, and it's crucial to realise that not every organisation will progress through all these stages successfully. In fact, most organisations encounter challenges and may not reach the final stage. Let's delve deeper into this concept.
- Denial - This marks the initial stage when something new is introduced, and the typical reaction is "No." This response often stems from a lack of understanding. Individuals may resist change because they are comfortable with the status quo, without delving into or attempting to comprehend the potential benefits of the change.
- Resistance - In this stage, people typically begin to grasp the reasons behind the change but may still struggle to fully comprehend its implications. While they are starting to get it, there is often a considerable amount of pushback, which can become repetitive.
- Acceptance - At this point, people may not yet know how to implement the change, but they are actively listening and engaged. The organisation is making significant progress, garnering support from a larger group.
- Exploration - People have now embraced the change, become open to asking questions, and are accepting of change while providing valuable feedback.
- Commitment - Individuals are highly motivated, taking ownership of the change initiative, and proactively driving it forward without external prompting.
- Growth - In this mature stage, people are actively seeking more feedback, willing to take calculated risks because they have gained confidence, and are even experimenting with new ideas.
Introducing SRE represents a significant organisational shift, particularly in environments where established processes are scarce. While it might seem relevant only for smaller organisations, it's surprising how even large data-focused companies can struggle with this issue. In some cases, critical data systems may rely on backends hosted on individual laptops.
Therefore, it becomes imperative to introduce SRE thoughtfully and strategically. Start by identifying the specific challenges within the organisation, collaborate closely with other teams and stakeholders, and articulate the benefits of enhanced reliability and performance without explicitly using the term "SRE." Instead, focus on how these improvements can contribute to achieving superior outcomes.
The four golden signals
This refer to a set of key performance indicators (KPIs) that are crucial for monitoring and assessing the health and reliability of a service or system. These signals are

- Latency - this defines things like how quickly a user gets a response from a request and is typically measured in milliseconds (ms). In the context of data this could mean how quickly data will arrive to an analytical database, typically measured in seconds or hours.
- Traffic - this typically refers to the volume of requests or data that flows into a service, application, or system. It encompasses the incoming network requests, such as web page views, API calls, user interactions, or any other form of communication with the system.
- Saturation - this refers to a condition where a system, component, or resource is operating at or near its maximum capacity or utilisation. When a system is saturated, it often indicates that it is experiencing a high volume of traffic or workload, and its resources, such as CPU, memory, or network bandwidth, are fully or nearly fully utilised. This can lead to performance degradation, increased latency, and potential service disruptions.
- Errors - this is what we are most accustomed to, and it might encompass scenarios such as encountering web request error codes within the 4XX or 5XX range, or in the realm of data, experiencing difficulties in obtaining valid data assets.
In summary, using the Four Golden Signals is a fundamental practice in SRE that enables organisations to maintain and improve the reliability of their services, leading to better user experiences, reduced downtime, and more efficient resource utilisation.
S.M.A.R.T in SRE
There is a SMART principle for everything, so why not SRE 😄
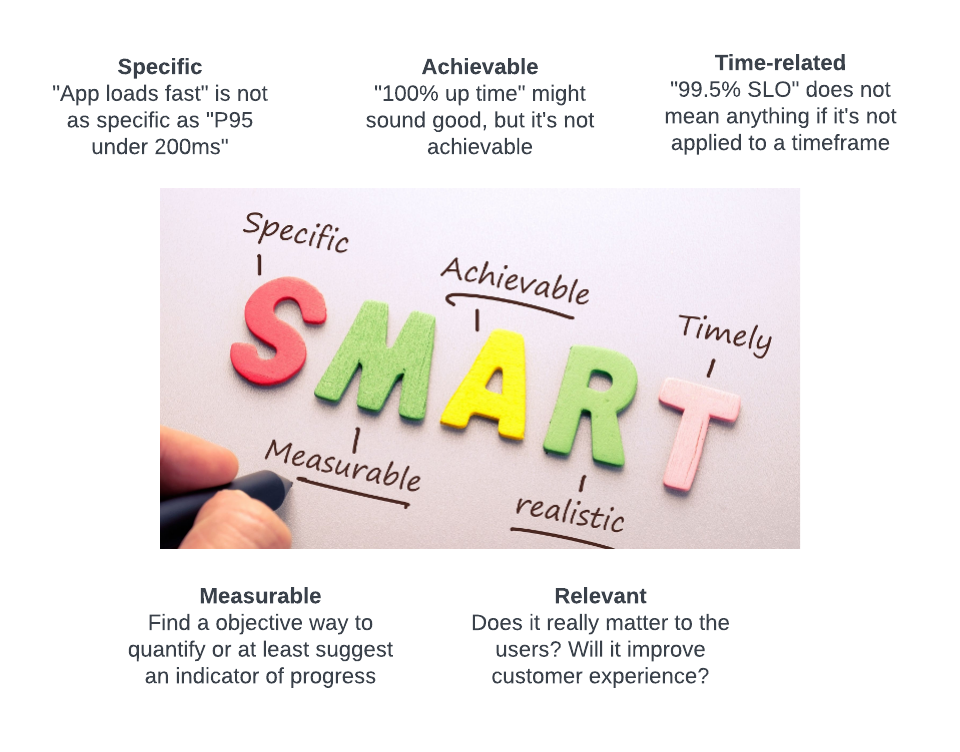
One of the prominent applications of employing the SMART framework in SRE lies in quantifying the enhancements in service reliability. It is imperative to avoid vague definitions, as they hinder effective measurement. For instance, stating that a system is exceptionally reliable and rarely experiences downtime lacks specificity, rendering it challenging to provide a consistent and quantifiable assessment.
Reducing Toil
Toil refers to repetitive, manual, and operational work that is often mundane and does not provide long-term value to the reliability or stability of a system. Toil is characterised by the following key attributes:
- Manual
- Repetitive
- Automatable
- Tactical
- Without enduring value
- Scales linearly as the service grows
An indicator of an excessive amount of toil is when the team frequently dedicates a significant portion of their time to repetitive operational tasks, like manually restarting service failures, attending to routine alerts, manually editing configuration files, or conducting routine data cleanup duties. These activities are generally low in terms of risk but consume a substantial amount of time. By diminishing the toil burden, the team can redirect their efforts towards more crucial tasks that would otherwise go underutilised, thereby enhancing the overall reliability of the service.
You might wonder why I haven't covered the details of assessing your Service Level Indicators (SLI), crafting your Service Level Objectives (SLO), or establishing Service Level Agreements (SLA). Well, these topics are widely known in the industry and readily available on the internet. The primary focus of this article is to illuminate the SRE framework, with the aim of aiding a broader audience in comprehending the significance of cultivating a cultural shift. We'll delve into the key aspects that matter to the business and present a straightforward and easily graspable framework that enables businesses to measure reliability in a meaningful way, rather than merely for the sake of technical implementation by engineers.
However, there's one aspect I'd like to emphasis, which is the timing of SLA definition. In my perspective, it's advisable not to rush into defining an SLA until the business has a clear requirement or at least demonstrates an interest in comprehending the value of measuring service reliability. It's important to note that the business might occasionally misuse the term "SLA" without a precise understanding of its implications. Nevertheless, these instances of interest or even inaccurate usage present opportunities to advocate for the concept of SRE. Ultimately, the goal is to measure and enhance the most critical reliability aspects to enhance the customer experience and maintain their satisfaction.
Comments ()