Serverless distributed processing with BigFrames
BigFrames, a library Google Cloud has recently introduced, it is marking a significant advancement in data processing.
BigFrames is in Preview at the time this blog post is written
And, now let's look at this in more detail.
Current Challenges in Distributed Processing
In the current complex data landscape, we frequently deal with distributed workloads that involve large datasets. These tasks often include data enrichment, filtering, and executing intricate transformations adhering to advanced rules. The workloads usually combine SQL-based tasks with Python for more sophisticated transformations. The task isn't considered complete until the results can be shared with others, typically requiring exporting to Google Cloud Storage (GCS) or conveying the data to downstream software services through a messaging system like Cloud Pub/Sub, to complete the task at hand end to end.
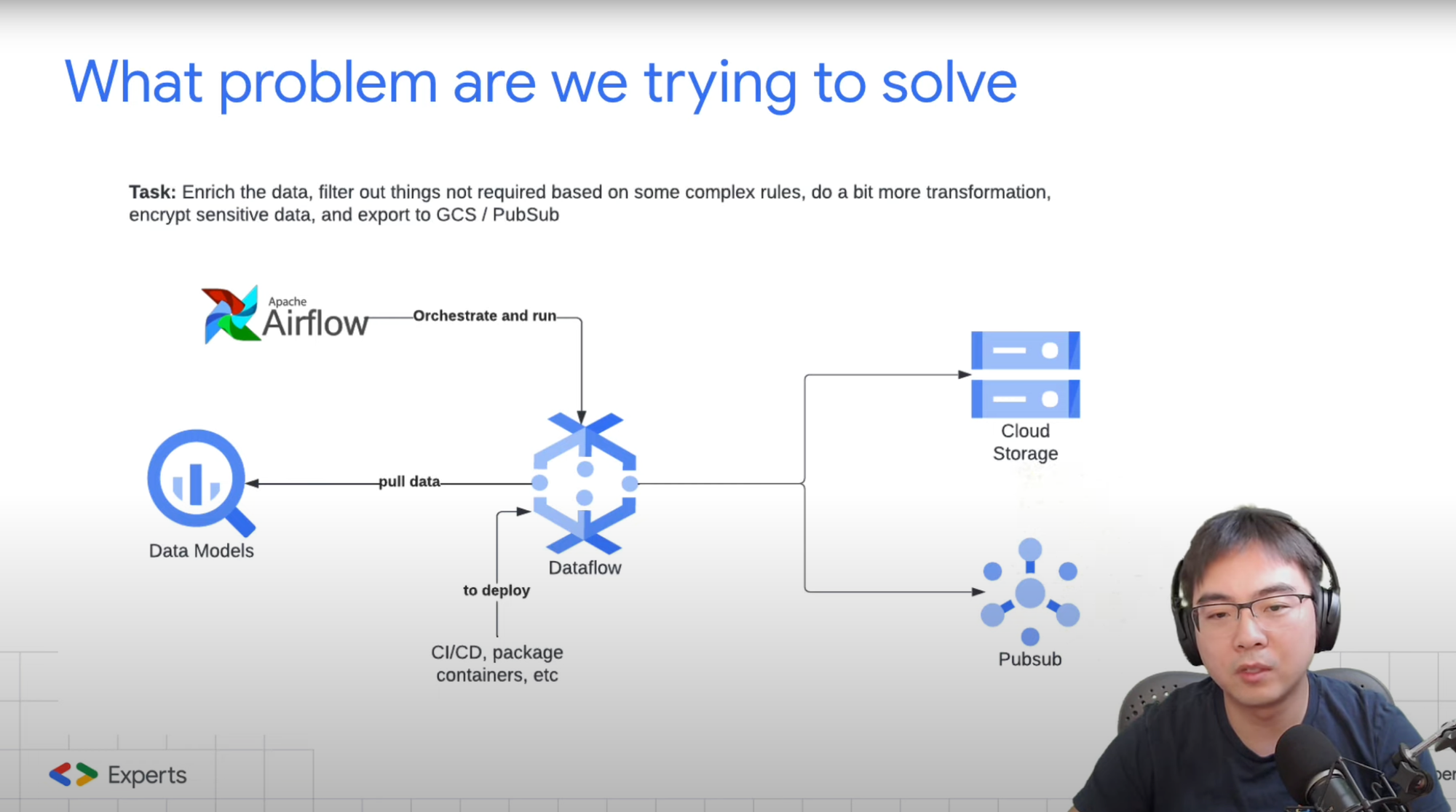
While these tasks can be executed using existing tools like DBT, BigQuery, or Airflow, they tend to complicate the processing workflow. The traditional method often involves using Airflow for orchestration and Cloud Dataflow for processing. This approach is complicated due to the steep learning curve of Apache Beam, which operates on Dataflow. Moreover, the deployment process in this setup is not straightforward, which requiring complex packaging and managing a range of dependencies.
What is BigFrames
My definition is that
It is an easy to learn, completely serverless distributed compute orchestration framework for batch processing
This library simplifies tasks traditionally handled by complex technologies like Apache Beam (on Dataflow) or Spark. It bridges the gap between local Pandas operations on Jupyter and deploying large-scale production workloads, enabling faster and more interactive development at scale.
BigFrames leverages BigQuery's serverless compute and uses Remote Functions on Cloud Run or Cloud Functions, providing a simpler, more modular method for managing tasks before embarking on machine learning workloads. This launch represents a major step forward in data processing, machine learning, distributed computing, and orchestration within the Google Cloud ecosystem.
A real world BigFrames use case
Consider the following flow
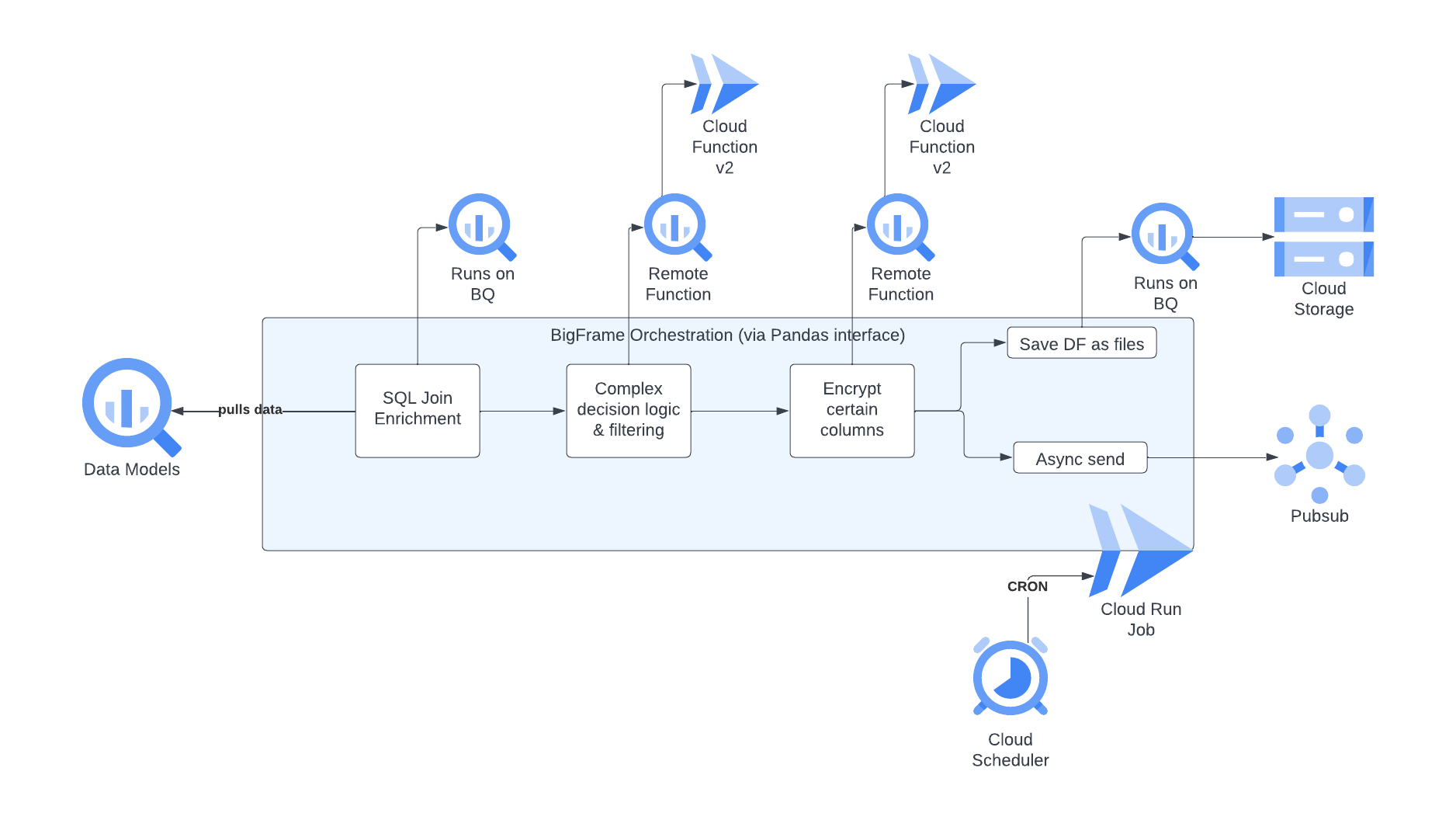
- Data models are provided in either a single or multiple BigQuery tables.
- Execution of SQL-based transformations is necessary.
- Additionally, more intricate transformations are required, calling for Python usage, often along with extra dependencies.
- Encryption of specific data columns, particularly those containing Personally Identifiable Information (PII), is required.
- The processed data must be dispatched to one or two destinations: a GCS bucket and/or a Cloud Pub/Sub message queue.
And now let's break it down into how exactly it works
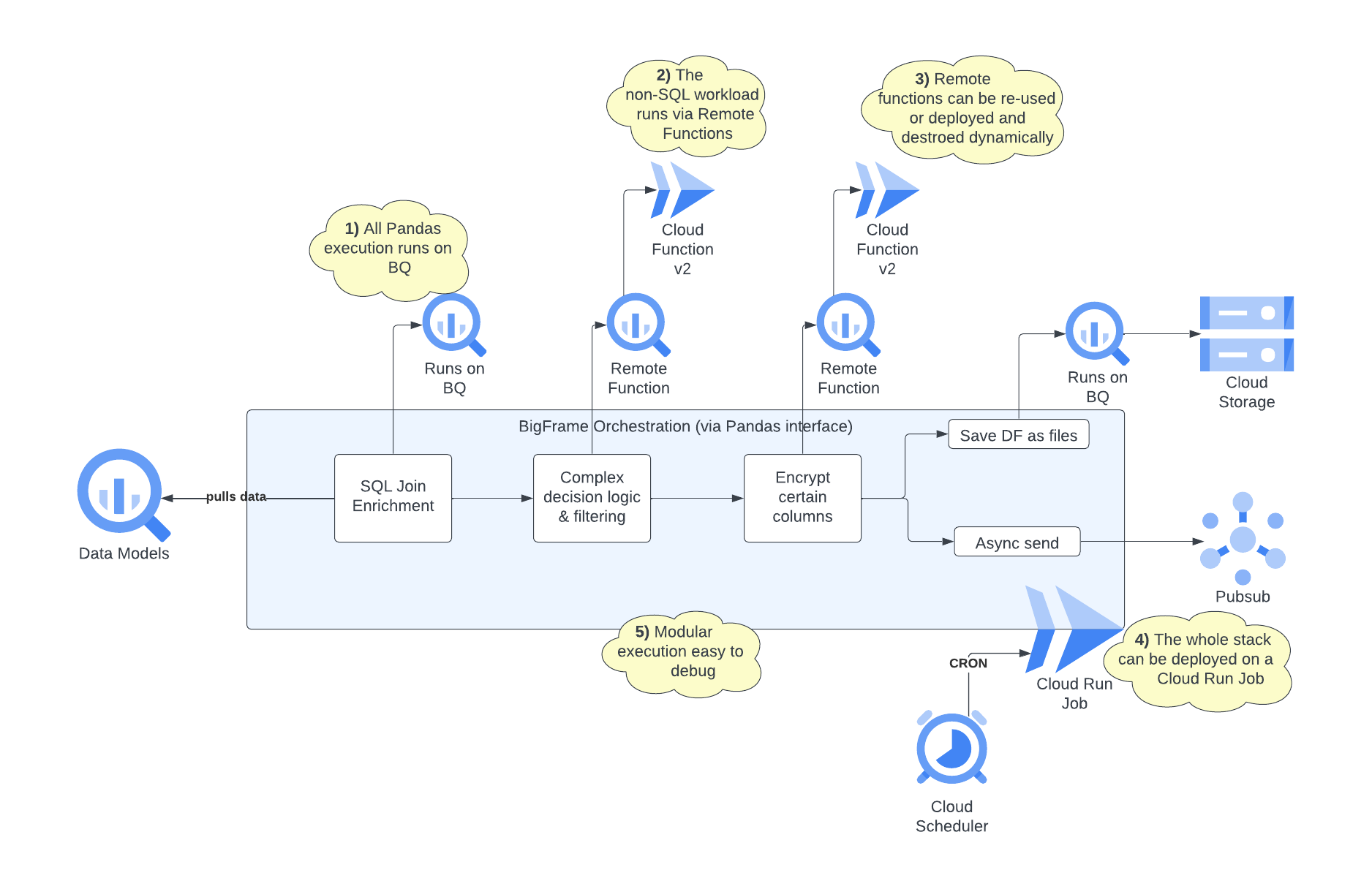
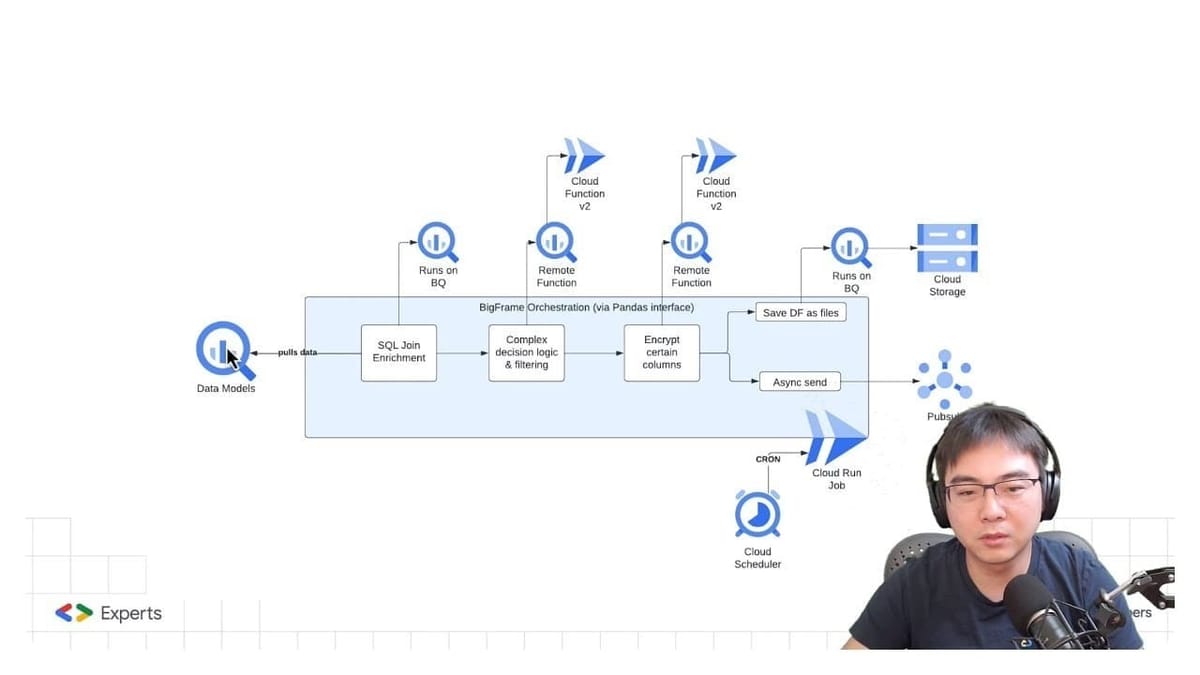
So that,
Execution of SQL-based transformations by using the Pandas library but delegating the execution to BigQuery, this means scaling is no longer an issue.
df["day_of_week"] = df["day_of_week"].map(
{
2: "Monday", 3: "Tuesday", 4: "Wednesday", 5: "Thursday", 6: "Friday",
7: "Saturday", 1: "Sunday"
}
)More complex transformations are done using annotated Python functions, again via the Pandas library, with execution delegated to Remote functions.
@bpd.remote_function(
[int],
str,
bigquery_connection="bigframes-rf-conn",
reuse=True,
packages=[],
)
def get_mapped_duration(x):
if x < 120:
return 'under 2 hours'
elif x < 240:
return '2-4 hours'
elif x < 360:
return '4-6 hours'
elif x < 480:
return '6-8 hours'
elif 480 <= x < 1440:
return '8-24 hours'
else:
return '> 24 hours'Encryption requires additional dependencies to be installed, managed by annotated python functions, with execution delegated to Remote functions.
@bpd.remote_function(
[str],
str,
bigquery_connection="bigframes-rf-conn",
reuse=True,
packages=["cryptography"],
)
def get_encrypted(x):
from cryptography.fernet import Fernet
# handle missing value
if x is None:
x = ""
else:
x = str(x)
key = Fernet.generate_key()
f = Fernet(key)
return f.encrypt(x.encode()).decode()Finally, transformed data can be directly saved into a GCS bucket or sent as events to Cloud Pub/Sub all in the same place by extracting data out of the Pandas dataframe.
The best part, is that all the steps mentioned here, only requires a single Cloud Run Job to be deployed to manage all the creation of resources and execution.
The whole example source code can also be found on Github with a Demo and also code explained if you are interested.
BigFrames pros and cons
OK, let's summarise the pros and cons, with some ideas as food for thought. And for a more detailed explanation of these points, it would be easier to head to the last section of the video.
- Orchestrate complex transformation using BigQuery and Remote Functions
- End to end serverless stack
- Dynamically creation of Remote Functions, faster development cycle
- Cannot configure dynamically created Remote Functions
- Does not have an easy way to maintain dynamically created Remote Functions
- Ingress rule is public for dynamically created Remote Functions
- Interactive development at scale in Jupyter Notebooks
- Swap Pandas to BigFrames at ease
- .to_pandas() for lightweight processing
- Connects to ML workload
#BigFrames #RemoteFunctions #DistributedCompute
Comments ()