Automated data profiling and quality scan via Dataplex
Data quality is a critical concern within a complex data environment, particularly when dealing with a substantial volume of data distributed across multiple locations. To systematically identify and visualise potential issues, establish periodic scans, and notify the relevant teams at an organisational level on a significant scale, where should one begin?
This is precisely where the automated data profiling and data quality scanning capabilities of Dataplex on Google Cloud can prove invaluable. Requiring no infrastructure setup and offering a straightforward method for defining and implementing rules for data profiling and quality checks, it could serve as an excellent foundation for your large-scale data quality framework.
Data Profiling vs Data Quality Scan
Data profiling, which analyses and summarises data characteristics, and Data Quality Scanning, which systematically examines data against set quality standards.

Understanding these processes is crucial for maintaining high data quality in large-scale environments.
Dataplex auto profiling
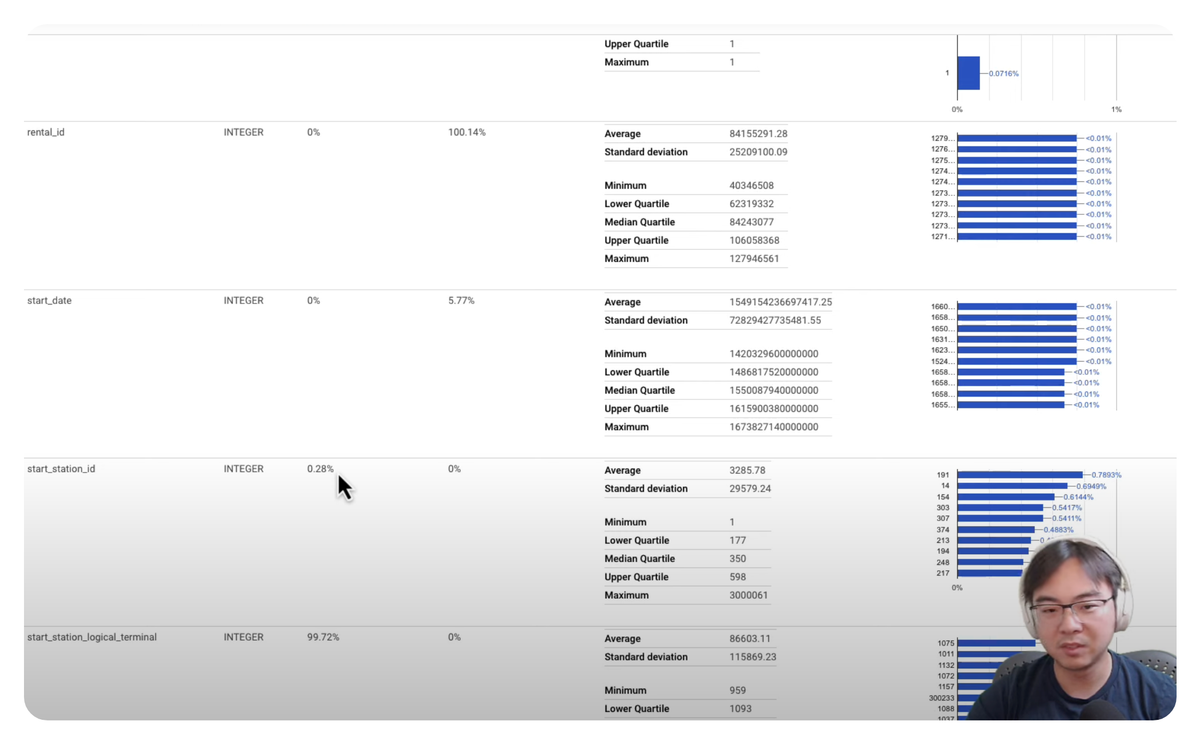
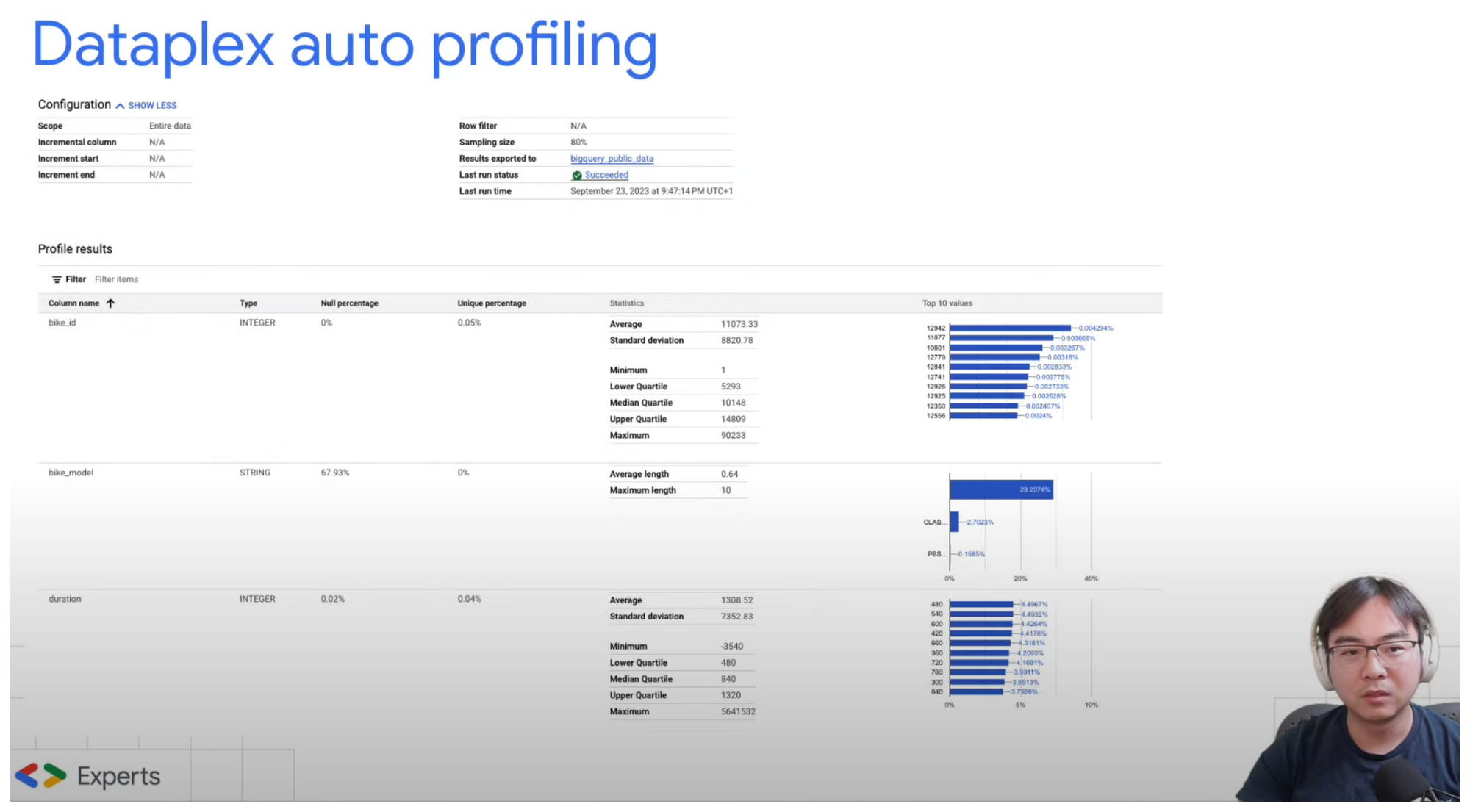
Dataplex auto profiling can be very handy when you have large amount of data assets and you don't necessarily have sufficient knowledge about what they are, or what the overall quality looks like.
Depends on the data types, the profiling results can contain different information. But for all columns types, it typically will give you a good idea on
- Percentage of null values
- Percentage of approximate unique (distinct) values
- Top 10 most common values
And for Numeric and String columns, it also shows
- Numeric column: Average, standard deviation, minimum, approximate lower quartile, approximate median, approximate upper quartile, and maximum values.
- String column: Average, minimum, and maximum length of the string.
So imagine, you have thousands of tables on BigQuery, and have no idea what the quality or distribution of the data may look like, this can give you a very good place to start, which can later on be used as the basis of data quality scans.
Dataplex auto data quality scan
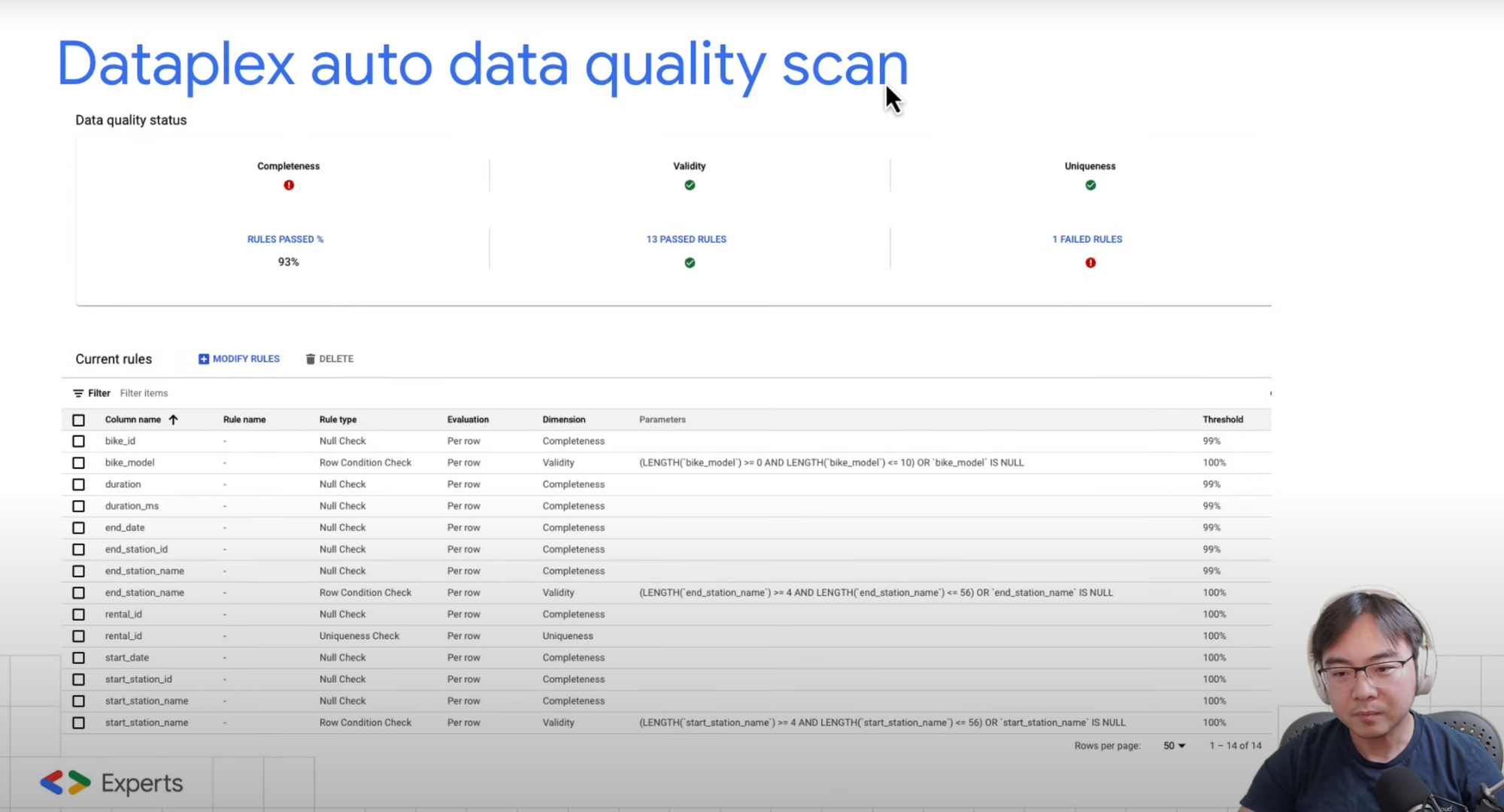
If you already have a good idea on what data quality rules to apply, or have a good set of profiling results generated by Dataplex auto profiling, now it's the time to put these into action.
Dataplex auto data quality scan uses something called Dimensions to set quality checks on each column. There are 7 dimensions in total and you can apply one of more dimensions to every column. Here is a list of all the most useful dimensions in my opinion, with an example on how they can be used.
| Dimension | Column | Rule | Rule parameters | What does it do |
|---|---|---|---|---|
| Completeness | amount | Null check | Threshold: 100% | Does not allow null |
| Validity | customer_id | Regex | Regex: ^[0-9]{8}[a-zA-Z]{16}$ Threshold: 100% |
Matching given format |
| Validity | transaction_timestamp | SQL | SQL: TIMESTAMP(transaction_timestamp) < CURRENT_TIMESTAMP() Threshold: 100% |
timestamp must not in the future |
| Validity | discount | Agg | 30<avg(discount) AND avg(discount) <50 Threshold: 100% |
Discount within range |
| Uniqueness | transaction_id | Uniqueness check | N/A | Must be unique |
You can see these checks are quite powerful. Not only it can do the simple things like null or uniqueness checks, which in the past are usually done through a lot of repetitive SQL, but also allowing very complex checks to be done via Regex and SQL.
It's also important to point out that the checks are not just row level checks, it can do very advanced stuff across an entire column via aggregated rules, such as making sure average discount is applied within a given range.
Have a play with the sample rules to see what works best for you.
Profiling hinted quality rules & YAML via CLI
One thing I found very useful, is that the data quality rules can be generated based on a previously generated data profiling results
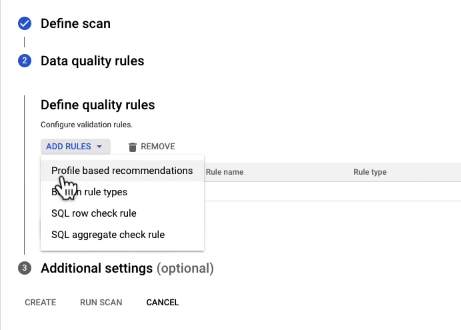
And as long as a table has been previously profiled, you could get something like this.
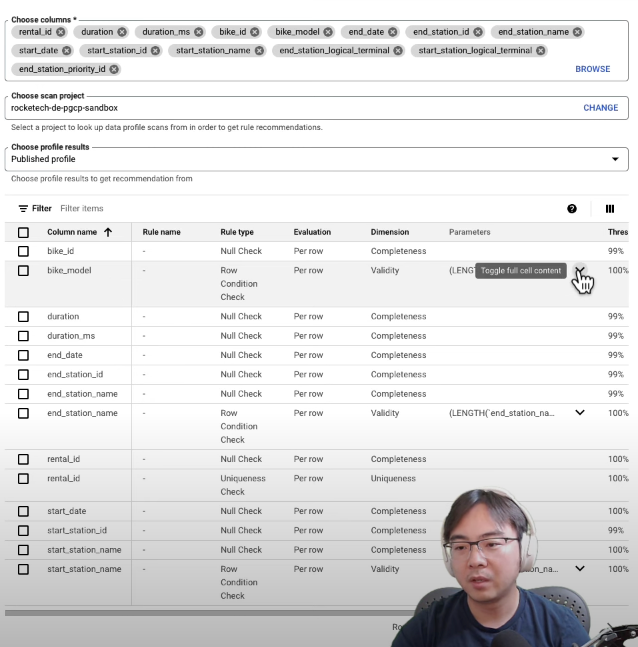
This acts as a solid baseline template, saving you from starting every project from ground zero. In the example I'm showing, it's great to see every column already filled in, which you can then tweak or build upon easily.
One snag, though, is the apparent lack of a simple method to export the rules that are generated from these profiling recommendations. To handle this efficiently, especially at a larger scale, my preference leans towards compiling all the data quality rules in a readable format, like YAML, and keeping them under version control. This way, it's much simpler to amend the rules directly in the code, rather than repeatedly navigating back to the UI.
A positive point about the Dataplex data quality scan is its CLI tool's support for YAML. I've put together a basic proof of concept on extracting these auto-generated data quality rules into a YAML file. I'm sharing this in the hopes that you might find it useful as well.
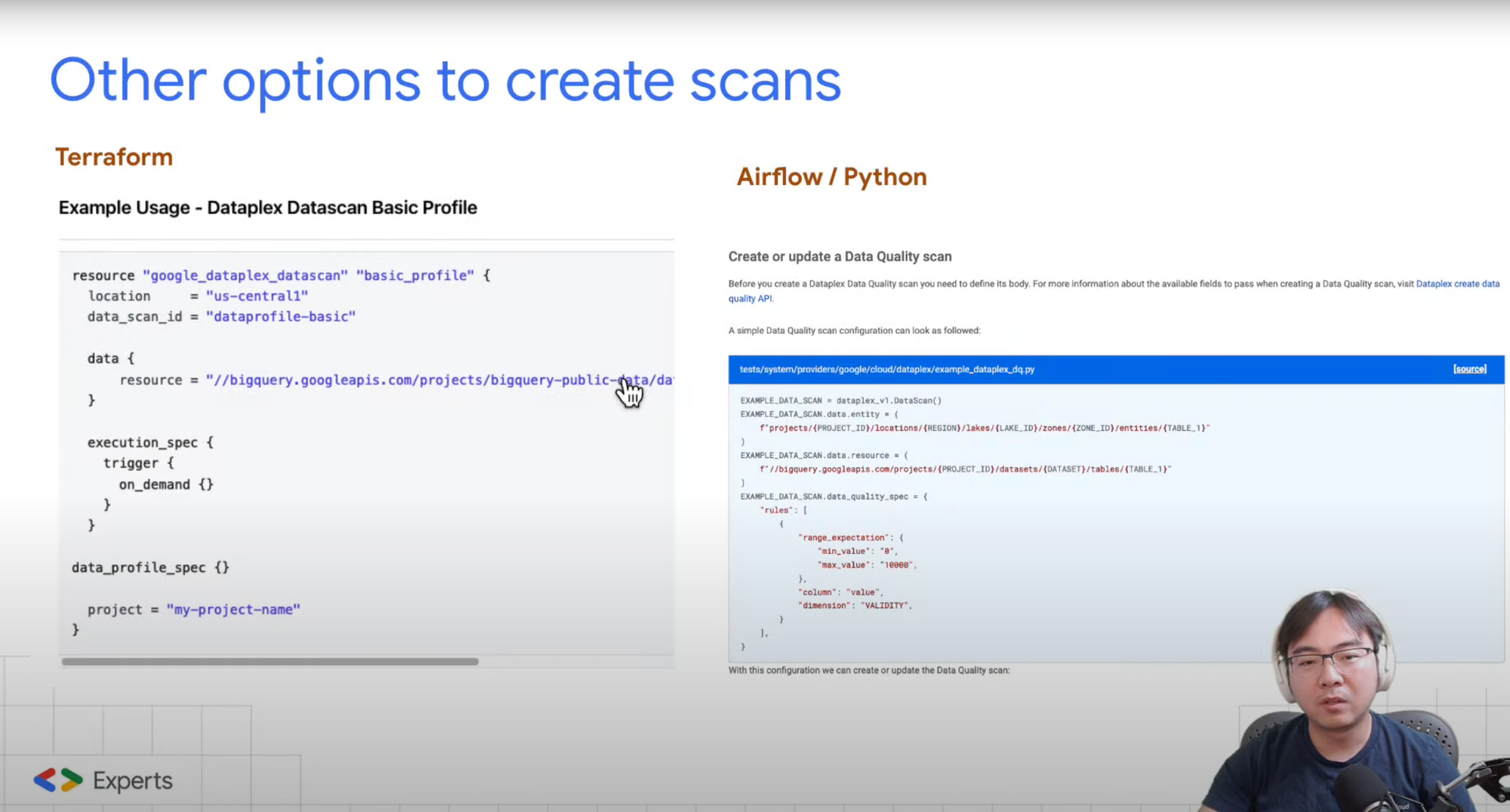
Other options to create scans
In addition to the Console and YAML option, there are also other ways you can go about creating Automated Data Quality Scans in Dataplex.
However, I find these methods somewhat confusing and difficult to use. I've outlined them in this section of the video below. But personally, I'd rather stick with YAML and CLI because it's straightforward to maintain the rules using version control. If any changes are needed, you can simply rerun the CLI.
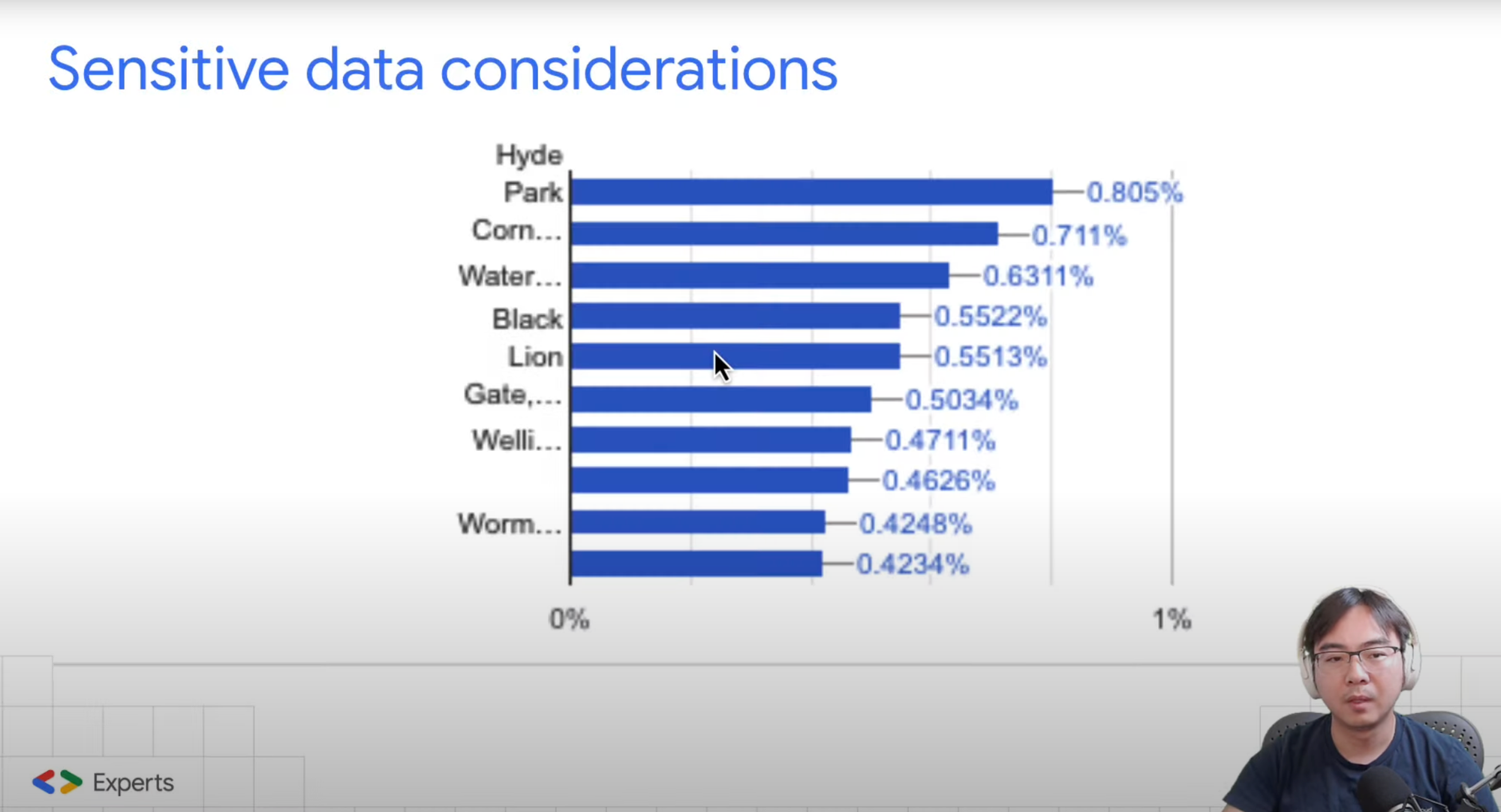
Sensitive data considerations
One important aspect to take into account is the potential for inadvertently exposing PII (Personally Identifiable Information) in the profiling results.
Although these results primarily consist of statistical data and are not usually tied to a specific individual, there remains a chance that they could reveal sensitive information like names and dates of birth, depending on how the data is organised, particularly within categories such as the "top 10 common results."
There are filters available that allow you to exclude columns containing PII, but it's important to weigh the advantages and disadvantages of applying these filters selectively, rather than implementing them as a universal rule.
Summary with pros and cons
Finally let's review Dataplex's automated profiling and quality scanning capabilities by looking at the pros and cons.
● Can easily profile large amount of tables to find potential data quality issues
● Can make recommendations on what to quality check based on profiling results
● YAML based data quality scan configuration is handy
● Integration with many data governance vendor (still needs to be verified)
● No easy way to export the recommendations of data quality checks via profiling
● Cannot see how to use YAML with Terraform
● Documentation is somewhat incomplete

Remember you can always watch the full video here on YouTube and I hope this has been helpful to get you started on scaling your data profiling and data quality scans using Dataplex 🙂
Comments ()